EmToM: An Evolving Benchmark for Embodied Theory of Mind

Abstract
Theory of Mind, the ability to track others' epistemic state, is what makes humans efficient decentralized collaborators. This ability is also required by AI agents in multi-agent settings to avoid duplicating effort, communicate efficiently, anticipate what other agents will do and plan accordingly. Existing benchmarks measure literal Theory of Mind by prompting agents with explicit questions about others' beliefs, but fail to measure functional Theory of Mind, whether agents can infer and act on others' mental states without being asked. We present EmToM, a benchmark to measure functional Theory of Mind in embodied agents. These agents operate in 3D scenes under partial observability and information asymmetry. Each task in EmToM is formally verified to be solvable and to require a specific depth of epistemic reasoning; further, new tasks are generated to increase difficulty as models improve. Evaluating ten frontier models on EmToM, we find that the frontier models perform poorly on functional ToM tasks, exhibiting 5.3% pass rate while literal ToM probes scores above 30%. This shows that the models can report what others believe but cannot act on that knowledge. Manual analysis traces 93% of failures to epistemic coordination breakdown.
Key Results
We evaluate ten frontier models on 300 EmToM tasks spanning cooperative and mixed-motive settings. On the hard variant (10/90 seed ratio), all models converge to 2.6–5.3% functional accuracy while literal ToM scores remain above 30%, confirming that literal and functional ToM are distinct capabilities: models can report what others believe but cannot act on that knowledge.
| Model | EmToM Standard (20/80) | EmToM Hard (10/90) | ||
|---|---|---|---|---|
| F | L | F | L | |
| Gemini-Flash | 20.7 | 34.0 | 5.3 | 38.6 |
| Haiku | 15.3 | 32.1 | 5.3 | 33.7 |
| Gemini-Pro | 18.7 | 35.5 | 5.3 | 40.5 |
| Opus | 15.3 | 32.1 | 5.3 | 33.7 |
| Sonnet | 12.0 | 39.0 | 2.6 | 45.8 |
| DeepSeek-v3.2 | 12.0 | 34.6 | 5.3 | 36.1 |
| GPT-5.4 | 10.7 | 30.4 | 3.9 | 30.0 |
| Kimi-K2.5 | 10.7 | 34.0 | 5.3 | 33.7 |
| O3 | 5.3 | 45.9 | 5.3 | 47.0 |
| GPT-5.4-mini | 4.7 | 30.8 | 2.6 | 31.3 |
Table 1. Functional (F, task pass rate %) and Literal (L, belief probe accuracy %) ToM on standard and hard benchmarks. On the hard subset, functional scores collapse to 2.6–5.3% while literal scores remain high (30–47%).
Analysis
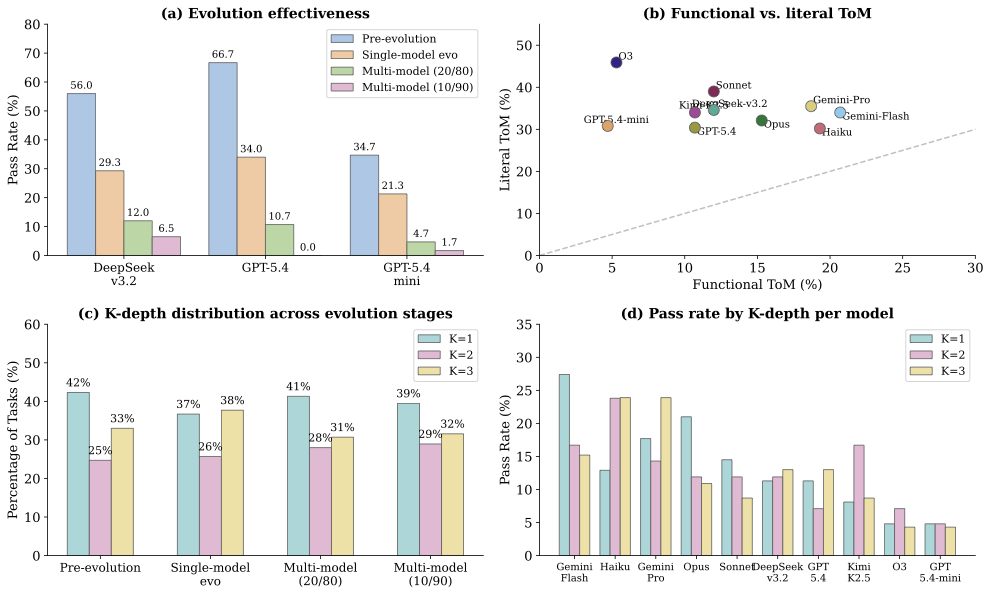
Figure 2. (a) Evolution effectiveness: pass rates drop monotonically across evolution stages. (b) Functional vs. literal ToM: all models fall above the diagonal, with O3 showing the largest gap (−40.6pp). (c) K-depth distribution stays balanced across evolution stages. (d) Models struggle even at K=1, confirming the bottleneck is epistemic coordination itself.
Failure Modes
Manual analysis of 40 randomly sampled failures reveals five distinct failure modes, with 93% tracing to epistemic coordination breakdown:
- Withholding critical information (7/40): An agent holds information a partner needs but fails to communicate it before the partner acts on a wrong guess.
- Epistemic chain breakdown (8/40): Agents complete a physical action but fail to inform partners who need to know about it.
- Private objective sabotage and disclosure: In mixed-motive tasks, agents sabotage shared goals or reveal conflicting private objectives in their first messages.
- Misallocating scarce messages (4/40): Agents waste their limited message budget on the wrong recipient or low-priority content.
- Not modeling partner constraints: Agents request partners to act in rooms they are barred from, or pick up objects they are already holding.
The EmToM Framework
EmToM uses an agentic task generation framework where an autonomous coding agent authors multi-agent ToM tasks inside a sandboxed workspace, invoking verifiers that ensure each task is logically solvable, physically executable, and genuinely requires epistemic reasoning. Three verification tools validate each task:
- PDDL Parsing: Confirms syntactic validity and computes the epistemic K-depth of the goal.
- LLM Judge Council: Two LLMs independently score each task on eight criteria requiring unanimous agreement.
- Structural Calibrator: Runs tasks in a baseline condition to ensure physical executability.
The benchmark evolves with model capabilities: as pass rates rise, the generation loop produces harder tasks targeting unsolved epistemic patterns. Seed tasks are biased 80/20 toward current model failures, creating evolutionary pressure without changing the generation infrastructure.
Orders of Theory of Mind
EmToM tasks require reasoning at different epistemic depths, connected to level-k reasoning from behavioral game theory:
| Order | Formal | Everyday Analogy |
|---|---|---|
| 0 — No ToM | φ | You open the fridge because you are thirsty. No one else is involved. |
| 1 — Self-aware | Ka(φ) | You can't reach the top shelf, so you ask your roommate to check if the jar is there. |
| 2 — Other-aware | Ka(Kb(φ)) | Your roommate left before the package arrived. You know they don't know it's here, so you text them. |
| 3 — Recursive | Ka(Kb(Kc(φ))) | You need your manager to know the client got the contract. Your assistant sent it, so you ask them to confirm they told the manager. |
Frontier models reliably handle order 1 but fail at order 2 and above.
BibTeX
@article{emtom2026,
title={EmToM: An Evolving Benchmark for Embodied Theory of Mind},
author={Gurusha Juneja and Dylan Lu and Saaket Agashe and Parth Diwane and Edward Gunn and Jayanth Srinivasa and Gaowen Liu and William Yang Wang and Yali Du and Xin Eric Wang},
year={2026},
url={https://emtom-bench.github.io}
}